
Build trust into your coding models
Proactively remove systemic flaws from training data to train foundational models that are secure by design.
Large language models are powerful but inherit flaws from their training data. SonarSweep is a service designed to remediate, secure, and optimize the coding datasets used in model pre-training and post-training.

AI is generating code faster than teams can govern it. Sonar was named a Leader, and placed highest on Ability to Execute. We built the verification layer the AI development cycle actually needs.
The quality of AI-generated code is tied to the quality of the data LLMs were trained on. Research shows that even a small amount of poor-quality data can disproportionately “poison” a model, leading it to generate buggy, insecure code.
Vast public datasets, the foundation for most LLMs, are a chaotic mix of good code and snippets riddled with bugs and security vulnerabilities.
During training, the LLM internalizes these flawed patterns, unable to distinguish good code from bad. It learns to replicate the same mistakes it was taught.
The LLMs in turn reproduce bugs and vulnerabilities as they generate code, which can make its way into the product and requires rigorous verification.
Generative AI is transforming how we code, but LLMs have a critical limitation: they often produce code with hidden bugs, security flaws, and maintainability debt. For LLM providers and companies who require a higher standard of quality, there is a clear need to fine-tune and customize models. SonarSweep provides the essential data quality layer for:

Build models that are secure and reliable by design by improving the training data at the source, giving their customers a competitive edge in the market.

Develop custom models with confidence in private environments, helping their customers to meet strict compliance requirements and protect sensitive IP.
Create high-performance, cost-effective Small Language Models (SLMs) for specialized agentic workflows on platforms like Databricks and IBM.

Achieve state-of-the-art performance on a budget by optimizing training datasets to build more powerful models with less data and compute.


SonarSweep automatically analyzes and fixes thousands of bugs, vulnerabilities, and code quality issues within the training dataset at scale.

A strict filtering process is applied to remove low-quality code. The refined dataset is then balanced to ensure diverse and representative learning for robust model capabilities.

The final, “swept” dataset is an optimized, high-quality asset ready for model training, yielding significant improvement in the quality of generated code.
Proactively remove systemic flaws from training data to train foundational models that are secure by design.
SonarSweep leverages Sonar’s industry-leading code analysis engines to automatically process large volumes of training code, remediate issues, and transform flawed data into high-quality training examples.

By fixing code instead of deleting it, we retain valuable learning examples for the model, improving its understanding of complex patterns.

Our engine turns bad examples into good ones, systematically raising the overall quality and security posture of the entire dataset.

Powered by the same analysis trusted by over 7 million developers to secure 700 billions of lines of code worldwide.
SonarSweep is now available in early access. Partner with Sonar to be among the first to build the next generation of safe, reliable, and secure coding models.
4.6 / 5
SonarSweep is a product from Sonar that remediates, secures, and optimizes coding datasets used to train AI language models. It is designed for AI companies and model builders — not for software development teams managing their own codebases.
Coding LLMs are typically trained on large volumes of publicly available open-source code, which frequently contains bugs, security vulnerabilities, and poor patterns. Models learn from these flawed examples and reproduce — and in many cases amplify — those flaws in the code they generate. SonarSweep addresses this at the root by cleaning and improving the training data before it is used to train or fine-tune a model.
SonarSweep shares its underlying code analysis engines with SonarQube and SonarQube Cloud, but it is a completely separate service and does not integrate with either product. It is not an add-on, extension, or feature of any SonarQube edition.
Where SonarQube and SonarQube Cloud help development teams detect quality and security issues in their own application code during development and CI/CD, SonarSweep processes large code datasets that AI companies use to train models. The relationship is a shared technological foundation — Sonar's analysis engines — applied to an entirely different use case and a different customer.
Coding LLMs are pre-trained on raw public open-source code — code that's full of bugs, vulnerabilities, and poor patterns. Models don't just absorb these flaws; they amplify them in everything they generate. SonarSweep fixes this at the source by cleaning training data before a model ever sees it.
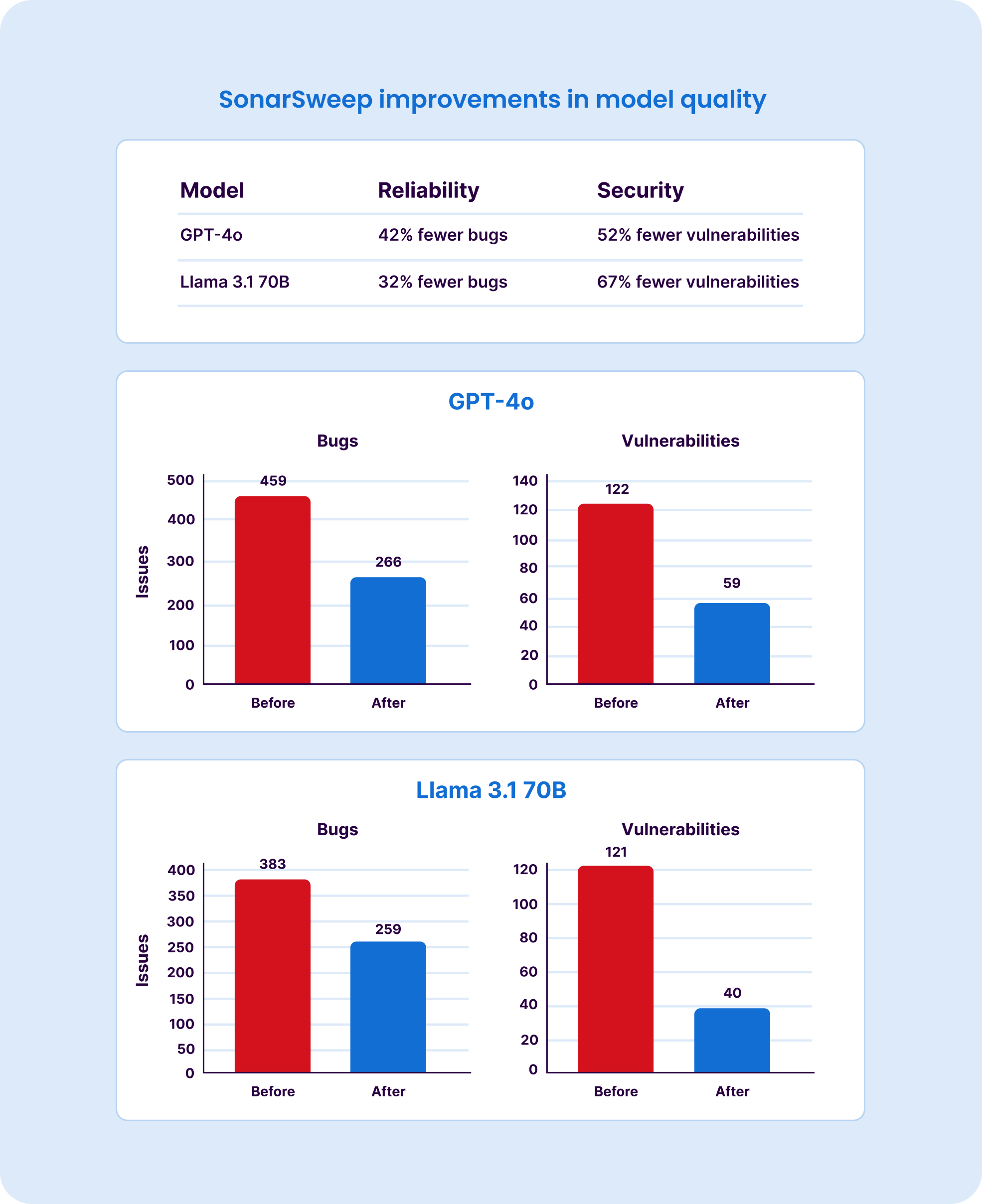
It reduces security vulnerabilities in model output by up to 67% and cuts bugs by up to 42%. It also handles a subtler problem: naively removing flawed code can skew language distribution in a dataset, so SonarSweep rebalances after cleaning to preserve model proficiency across all languages. And by addressing quality upfront, it eliminates the need for costly post-training correction passes.
SonarQube for IDE (formerly SonarLint) is a developer productivity tool that runs inside editors like VS Code, IntelliJ, and Eclipse, giving individual developers real-time feedback on quality and security issues as they write code. It operates at the developer level, in the IDE, during active development.
SonarSweep is not a developer tool at all. It is a data processing service for AI companies that are training or fine-tuning coding LLMs. It does not run in an IDE, does not provide feedback to developers, and is not part of a development workflow.
Yes — this is the core purpose of SonarSweep. The quality of code a language model generates is directly shaped by the quality of the data it trained on. A model that learned from code full of vulnerabilities and bugs will reproduce those patterns at scale. SonarSweep intervenes at the data stage, before training, to raise the quality floor of what the model learns from.
Models trained on SonarSweep-prepared datasets have demonstrated up to 67% fewer security vulnerabilities and up to 42% fewer bugs in their generated code compared to models trained on unswept data — with no degradation in functional performance. This was validated on the GPT-OSS-20B model.
SonarSweep supports 35+ programming languages, drawing on the full breadth of Sonar's code analysis engines — the same engines that power SonarQube and SonarQube Cloud.
In the context of LLM training data, this means SonarSweep can analyze, filter, and remediate code across all the languages that typically appear in large public code datasets: common back-end languages, front-end languages, scripting languages, systems languages, and more. Across these languages, it can identify and automatically fix over 6,700 distinct types of quality and security issues.
SonarSweep doesn't produce code changes for developers to review in pull requests. It processes and delivers cleaned training datasets to AI companies. Governance in this context sits with the AI team — validating dataset quality and model output before using the swept data in a training run.
No. SonarSweep has no connection to any SonarQube edition. It is a separate product for companies building or fine-tuning coding LLMs — not a feature unlocked through any SonarQube subscription tier.
The ROI is for AI companies, not development teams. Models trained on SonarSweep-processed data produce up to 67% fewer security vulnerabilities and up to 42% fewer bugs — with no loss in functional performance. It also reduces training cost by addressing data quality upfront, eliminating expensive post-training correction cycles.
